This is a blog entry about how sometimes you just get overwhelmed by UI and consequentially lost. I was looking into CAN on an STM32 dev board (the Nucleo C092RCT) when I ran into the strange issue that my little test programme would transmit CAN frames fine, but somehow not receive them.

Searching forums did not return anything that solved my issue. I did find posts stating that in order for CAN to work, you’d have to set the number of filters to 1 (Std Filters Nbr).
While it is true, that you need this in order to filter by criteria like the identifier, having the filter number set to 0 simply lets everything pass and so the HAL should in theory respond to any message on the bus.
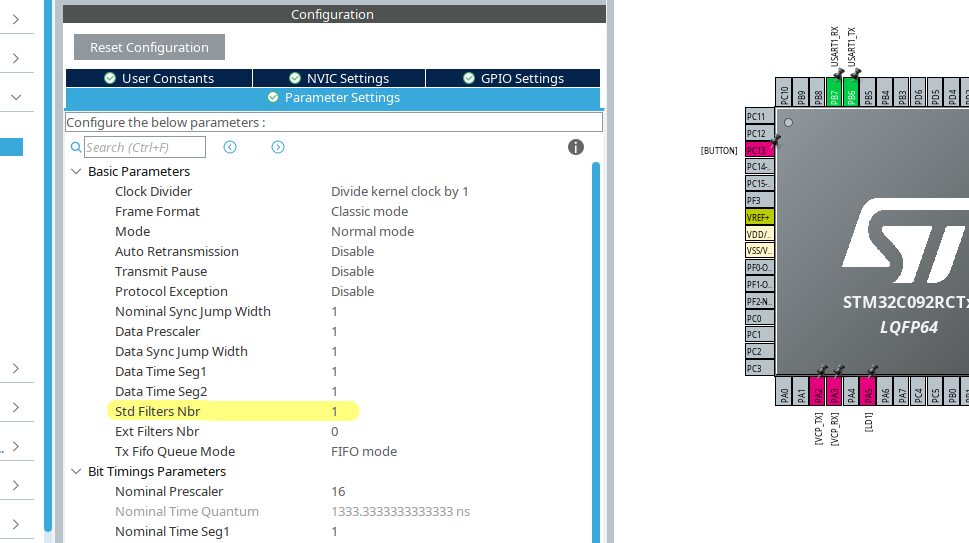
But since I wanted to filter by an ID, I set it anyway like so:
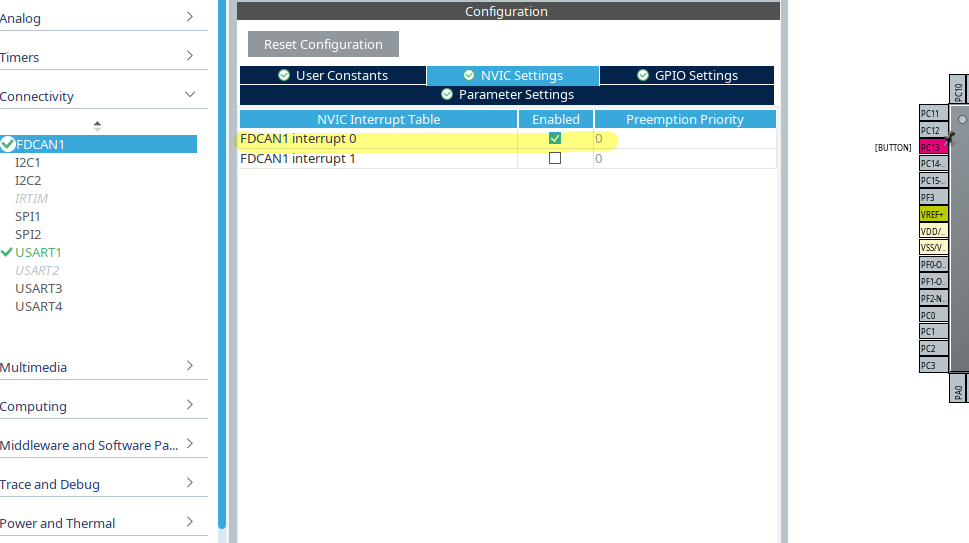
But then I though: “Let’s explore the UI of STM32CubeMX a bit more. And behold: There’s an interrupt tab called “NVIC Settings” that escaped my view before and FDCAN1 interrupt 0 is not enabled. Let’s change that like so:
And would you know it: Now sending a CAN frame with appropriate Identifier would actually cause the callback function HAL_FDCAN_RxFifo0Callback to be called and toggle my little green LED.
Some forum posts claimed you’d need to configure global filters by invoking HAL_FDCAN_ConfigGlobalFilter. And that is actually true. What got me, however, is the FilterType, where I have to admit I do not understand the behaviour of two of the three options: FDCAN_FILTER_DUAL seems pretty clear to me, it passes what matches either of the two filter IDs given by FilterID1 and FilterID2. FDCAN_FILTER_MASK however evades me. I guess it’s something like ID1 corresponding to a positive and ID2 to a negative mask (iduno). What confused me a lot was FDCAN_FILTER_RANGE which did not behave at all as I thought (my though: ID1 is the lower and ID2 the upper boundary of the range).
So here’s the snippet that actually worked for me:
static void FDCAN_Config(void) {
FDCAN_FilterTypeDef sFilterConfig;
// Rx Filters
sFilterConfig.IdType = FDCAN_STANDARD_ID;
sFilterConfig.FilterIndex = 0;
sFilterConfig.FilterType = FDCAN_FILTER_DUAL; // other options: FDCAN_FILTER_MASK, FDCAN_FILTER_RANGE
sFilterConfig.FilterConfig = FDCAN_FILTER_TO_RXFIFO0;
sFilterConfig.FilterID1 = 0x400;
sFilterConfig.FilterID2 = 0x321;
if (HAL_FDCAN_ConfigFilter(&hfdcan1, &sFilterConfig) != HAL_OK) Error_Handler();
if (HAL_FDCAN_ConfigGlobalFilter(&hfdcan1, FDCAN_REJECT, FDCAN_REJECT, FDCAN_REJECT_REMOTE, FDCAN_REJECT_REMOTE) != HAL_OK) Error_Handler();
// Start Module
if (HAL_FDCAN_Start(&hfdcan1) != HAL_OK) Error_Handler();
if (HAL_FDCAN_ActivateNotification(&hfdcan1, FDCAN_IT_RX_FIFO0_NEW_MESSAGE, 0) != HAL_OK) Error_Handler();
// Prepare Tx
TxHeader.Identifier = 0x321;
TxHeader.IdType = FDCAN_STANDARD_ID;
TxHeader.TxFrameType = FDCAN_DATA_FRAME;
TxHeader.DataLength = FDCAN_DLC_BYTES_4;
TxHeader.ErrorStateIndicator = FDCAN_ESI_PASSIVE;
TxHeader.BitRateSwitch = FDCAN_BRS_OFF;
TxHeader.FDFormat = FDCAN_CLASSIC_CAN;
TxHeader.TxEventFifoControl = FDCAN_NO_TX_EVENTS;
TxHeader.MessageMarker = 0;
}
void HAL_FDCAN_RxFifo0Callback(FDCAN_HandleTypeDef *hfdcan, uint32_t RxFifo0ITs) {
if ( (RxFifo0ITs & FDCAN_IT_RX_FIFO0_NEW_MESSAGE) != RESET) {
if (HAL_FDCAN_GetRxMessage(hfdcan, FDCAN_RX_FIFO0, &RxHeader, RxData) != HAL_OK) Error_Handler();
BSP_LED_Toggle(LED_GREEN);
printf("HAL_FDCAN_RxFifo0Callback! %s\r\n", (char*) RxData);
}I hope, this helps some. By the way: If you play with options in STM32CubeMX, double check the other options – they tend to get reset as you play with other values.

 becomes
becomes
 as a rational function
as a rational function